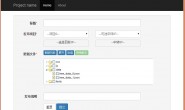
大家好,,之前写过一篇 python 递归实现Easyui combotree 树 ,是将svn的数据checkout到本地目录,然后递归目录实现的。在现实中,随着时间的推移,项目文件的增多,svn 的数据可能会比较庞大,第一浪费磁盘空间,第二递归目录实现比较慢。为了提高前端Easyui显示项目列表的效率,及提高空间利用率,现在用另外一种方法
1、通过 svn list 查看svn 文件列表生成一个列表文件
2、使用python 对svn 列表文件递归实现 easyui combotree 树
查看/生成 svn 列表文件
我这里简单搭建了一个svn ,svn地址为 svn://192.168.1.104 , 通过 svn list 查看列表
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
## 通过 svn list 查看svn列表 ,svn 具体的命令使用大家可以google [root@localhost ~]# svn list -R svn://192.168.1.104 huangdc.txt.txt python/ readme.txt.txt salt/ salt/modules/ salt/modules/m1.txt.txt salt/modules/m2.txt.txt salt/pillar/ salt/pillar/p1.txt.txt salt/pillar/p2.txt.txt test.txt.txt ## 可以看到svn 的文件了,将这些列表导入到一个文件中 [root@localhost ~]# svn list -R svn://192.168.1.104 > list.txt [root@localhost ~]# cat list.txt huangdc.txt python/ readme.txt salt/ salt/modules/ salt/modules/m1.txt salt/modules/m2.txt salt/pillar/ salt/pillar/p1.txt salt/pillar/p2.txt test.txt |
python 递归实现
创建一个python 文件 digui.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
#!/usr/bin/python ## 递归函数 line 是文件的一行,dir_list 是列表 def dao(line,dir_list): ## 切割,得到一个列表 dir_str dir_str = line.split('/') ## 判断行是否为目录 if str(dir_str[-1]) == "": if len(dir_str) == 2: dir_list.append({"id":str(dir_str[0]),"state":"closed","text":str(dir_str[0]),"children":[]}) else: i = 0 for dir_i in dir_list: if dir_i['text'] == dir_str[0]: line_min = '/'.join(dir_str[1:]) dir_list_min = dir_list[i]['children'] break i = i+1 ## 如果多层目录,就递归 dao(line_min,dir_list_min) else: ## 文件处理 if len(dir_str) == 1: dir_list.append({"id":str(dir_str[0]),"state":"open","text":str(dir_str[0])}) else: i=0 for dir_i in dir_list: if dir_i['text'] == dir_str[0]: line_min = '/'.join(dir_str[1:]) dir_list_min = dir_list[i]['children'] break i = i + 1 ## 如果多层目录,就递归 dao(line_min,dir_list_min) return dir_list ## 创建一个空列表 alist = [] ## 将list.txt 的内容全部读出来 with open("./list.txt",'r') as lf: file = lf.readlines() ## 将读出的行 循环一行一行处理 for i in range(len(file)): line = file[i].replace('\n','') alist = dao(line,alist) ## 将结果写入到一个文件中 #with open("./huangdc.json",'w') as lf: # lf.writelines(str(alist)) ## 讲结果打印出来 print "\n\n\nalist:\n",alist |
我们来执行看看结果:
|
1 2 3 4 |
[root@localhost ~]# python digui.py alist: [{'text': 'huangdc.txt', 'state': 'open', 'id': '65_huangdc.txt'}, {'text': 'python', 'state': 'closed', 'id': '65_python', 'children': []}, {'text': 'readme.txt', 'state': 'open', 'id': '65_readme.txt'}, {'text': 'salt', 'state': 'closed', 'id': '65_salt', 'children': [{'text': 'modules', 'state': 'closed', 'id': '65_modules', 'children': [{'text': 'm1.txt', 'state': 'open', 'id': '65_m1.txt'}, {'text': 'm2.txt', 'state': 'open', 'id': '65_m2.txt'}]}, {'text': 'pillar', 'state': 'closed', 'id': '65_pillar', 'children': [{'text': 'p1.txt', 'state': 'open', 'id': '65_p1.txt'}, {'text': 'p2.txt', 'state': 'open', 'id': '65_p2.txt'}]}]}, {'text': 'test.txt', 'state': 'open', 'id': '65_test.txt'}] |
好了 ,,, 测试过,一万多行的文件,也就是差不多一万个文件的一个svn list ,list 用时5s ,加上 python生成json只需要0.7s ;6s 不用就可以在前端显示出来
这样前端 easyui combotree 显示就会非常快 ,前端如何使用easyui 插件,可以查看 python 递归实现Easyui combotree 树
![[转] Python 之父谈 Python 未来](https://www.huangdc.com/wp-content/themes/yusi1.0/timthumb.php?src=http://www.huangdc.com/wp-content/uploads/2016/07/guido-python.jpg&h=110&w=185&q=90&zc=1&ct=1)